GIGA RESEARCH
Real-Time Hallucination Correction at Zero Latency Cost
We reduced voice agent hallucination rates from 4-5% to less than 1% in production without adding latency. LLMs generate text faster than humans can speak it. That speed gap is where we run detection.
Esha Dinne, Rishi Alluri, Arnab Maiti
May 7, 2026
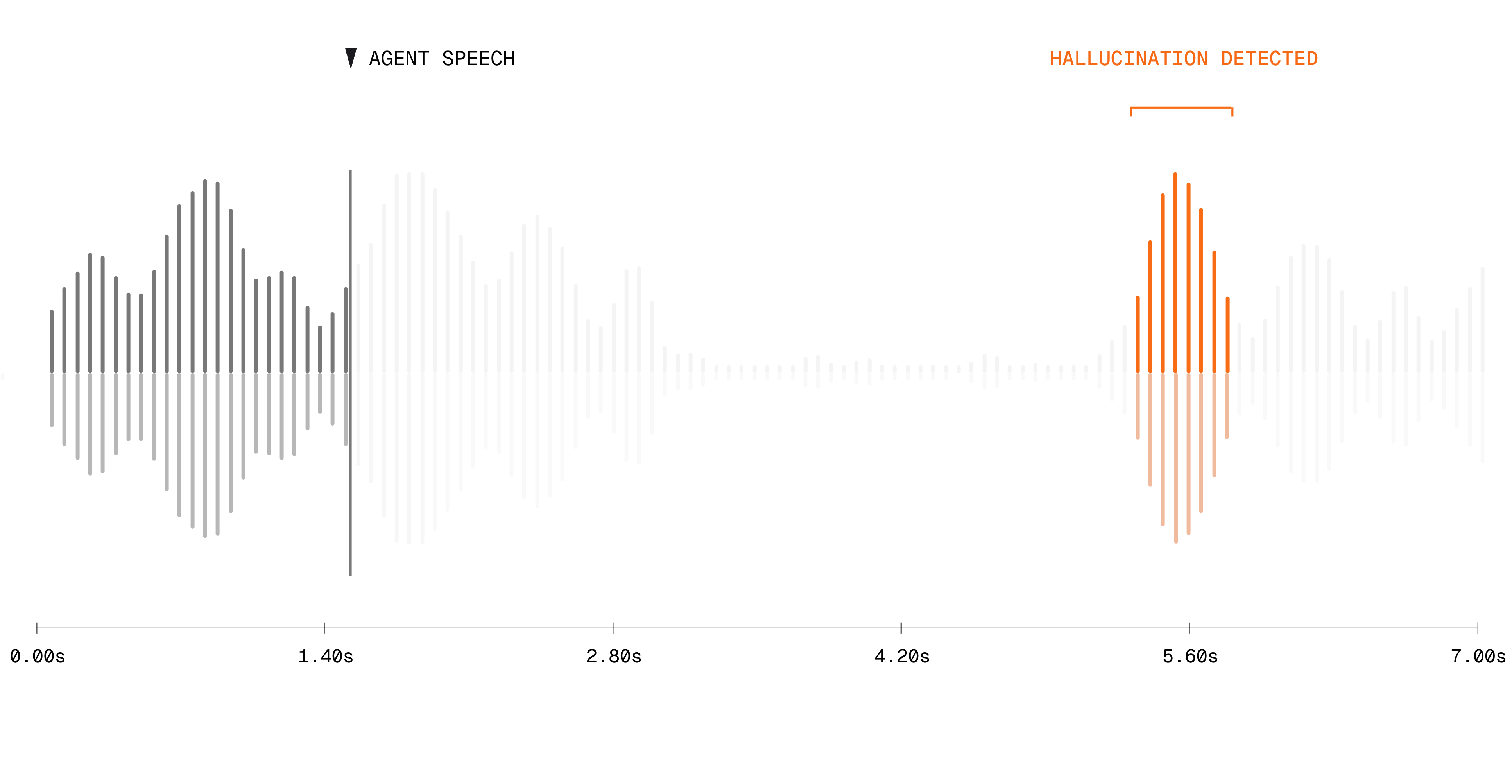
Why Hallucinations in Voice Are More Dangerous
A caller asks a voice agent about their copay. The agent says, "$0." The real amount is $40. The caller books the appointment, drives across town, and learns the truth at the front desk.
Voice makes this worse than text for two reasons.
You cannot use reasoning models for generation. Voice requires roughly one-second time to first byte, or the conversation feels broken. Reasoning models think before responding and hallucinate less, but their first token takes several seconds, which is too slow for voice. This forces voice systems to use non-reasoning LLMs, which are quicker but hallucinate more. The constraint that makes voice feel natural is the same constraint that makes it less accurate.
Spoken errors bypass verification. In text, a wrong answer stays on screen. The user can re-read it, question it, or check another source. In voice, the same answer arrives as a confident statement and then disappears. Listeners use a speaker's tone, rhythm, and emphasis to judge how certain and honest they seem, and those vocal cues can influence both perceived reliability and verbal working memory (Goupil et al., Nature Communications, 2021). The caller is more likely to act before verifying.1
These compound. The model hallucinates more because it cannot reason. The caller trusts it more because it sounds confident.
Why You Can't Just Verify Before Speaking
The standard fix: verify the response with a second model before the caller hears it. In text, this works. In voice, it adds 3 to 4 seconds of latency to every turn. TTFB goes to 3+ seconds. The caller hangs up.

You pay this on every turn, even on the 96% of turns where the model didn't hallucinate.
The Core Insight:
Throughput > Speaking Speed
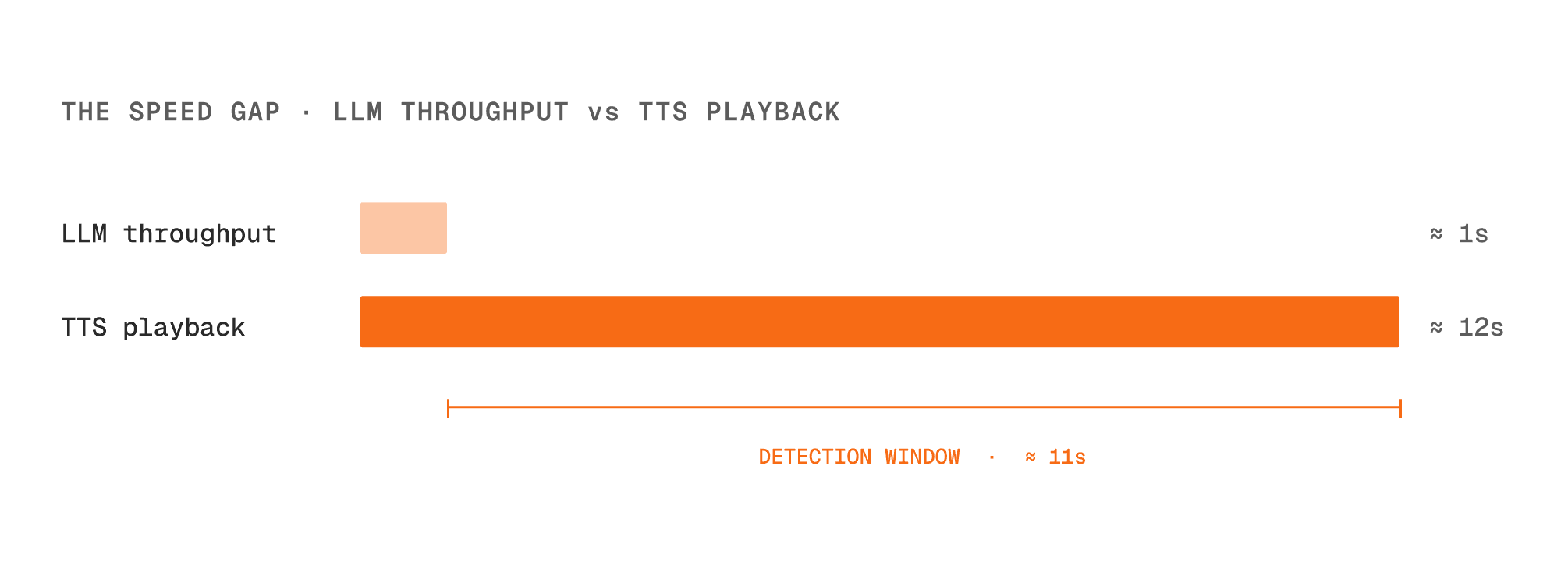
The right comparison is not raw tokens per second alone. A voice system first pays time to first token, then streams the remaining output. Using rough planning numbers, a recent low-latency model might take ~600ms to emit the first token and then stream at ~75 tokens per second. A 30-word response is roughly 40 output tokens, so the full text is available in about a second. Speaking those same 30 words takes about 10 to 12 seconds. That several-second gap between what has been generated and what has been heard is where we run detection.
This is not a small window. Even after including the initial latency, the full text usually exists many seconds before the caller finishes hearing it.
How It Works
Everything streams. As each sentence completes, two things happen simultaneously:
Path 1: Audio. The chunk goes to TTS and streams to the caller immediately.
Path 2: Detection. The same chunk goes to a reasoning model. It checks: does this contradict the instructions? Does it contradict something said earlier? Did the model make something up? Does the response adhere to all strict guardrails?2
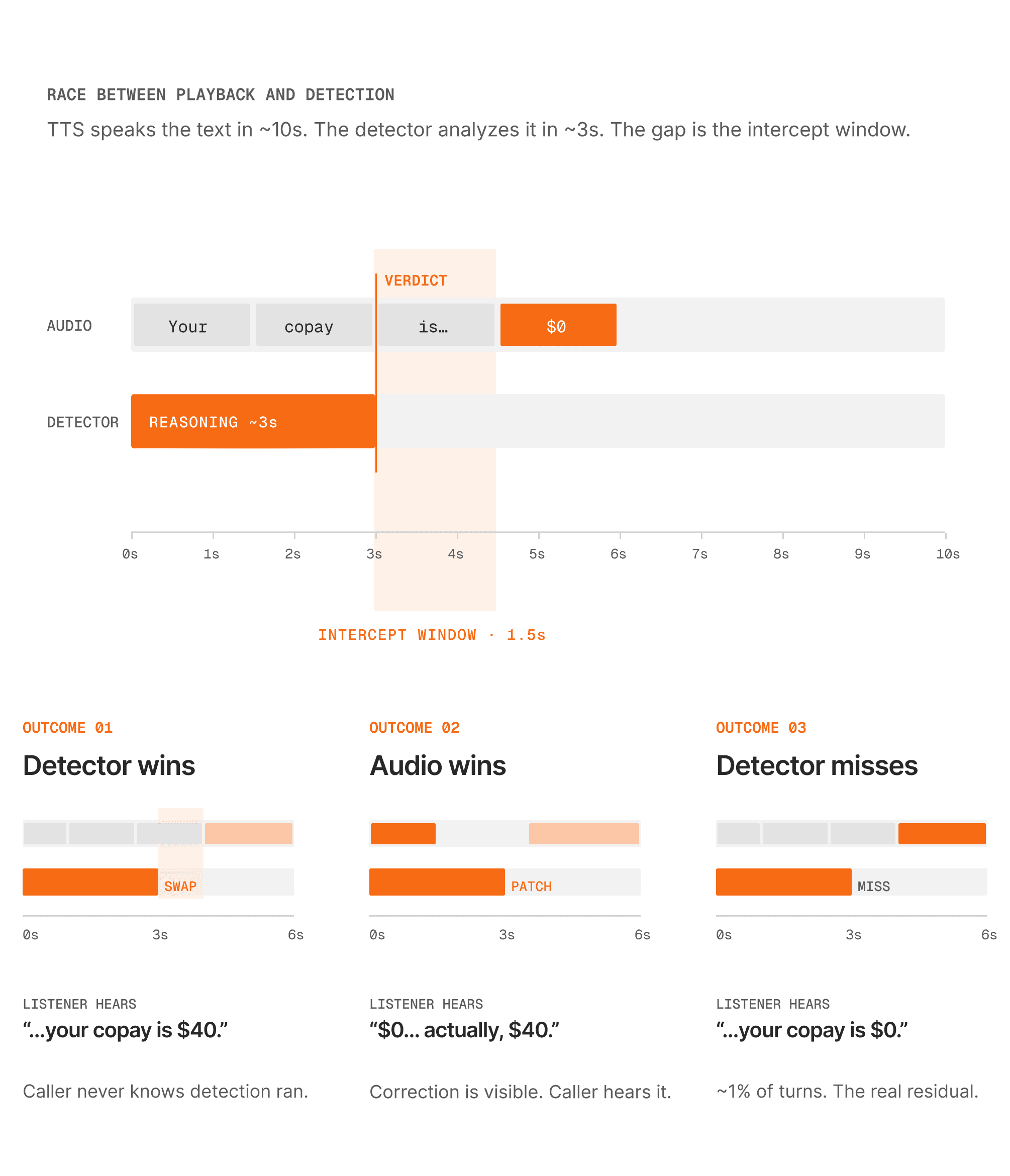
Audio never waits for detection. They race. Three outcomes are possible:
Outcome 1: Detector finishes before the hallucinated audio plays
This is the common case when the hallucinated claim appears late enough in the spoken response. The LLM makes the full text available in roughly a second, while TTS speaks it word by word over 10 to 12 seconds. The detector takes ~3 seconds. By the time the caller has heard "Your copay for specialist visits is..." the detector has already flagged "$0" as wrong. The system blocks the hallucinated audio from playing and substitutes the correct response. The caller hears:
No interruption. No correction phrase. No "let me correct that." The caller never hears the wrong answer. They never know detection was running. This experience is seamless.
Outcome 2: Hallucinated audio plays before the detector finishes
This happens on very short responses. If the entire response is "Your copay is $0" and TTS speaks it in under 2 seconds, the audio finishes before the 3-second detection pass completes. The caller heard the wrong answer. Now the agent needs to explicitly correct itself:
0:00/1:34
The "actually, let me correct that" bridge only exists in Outcome 2, because the caller already heard something wrong and needs to know it's being corrected. In Outcome 1, there is nothing to correct from the caller's perspective.
Outcome 3: Detector misses it entirely
No detection system is 100% accurate. In approximately 1% of turns, the detector does not flag the hallucination at all. This is not a timing problem. The detector simply got it wrong. The hallucination goes through uncorrected. Reducing this residual rate is a matter of improving detector accuracy, not architecture.
How Different Models Compare as Detectors
Not all detectors are equal. We built an internal benchmark tailored to our use case and evaluated three classes of models across the hallucination types that matter most for agent reliability: instruction contradictions (agent does something it was told not to do), context contradictions (agent contradicts itself mid-conversation), and fabrications (agent invents information).3
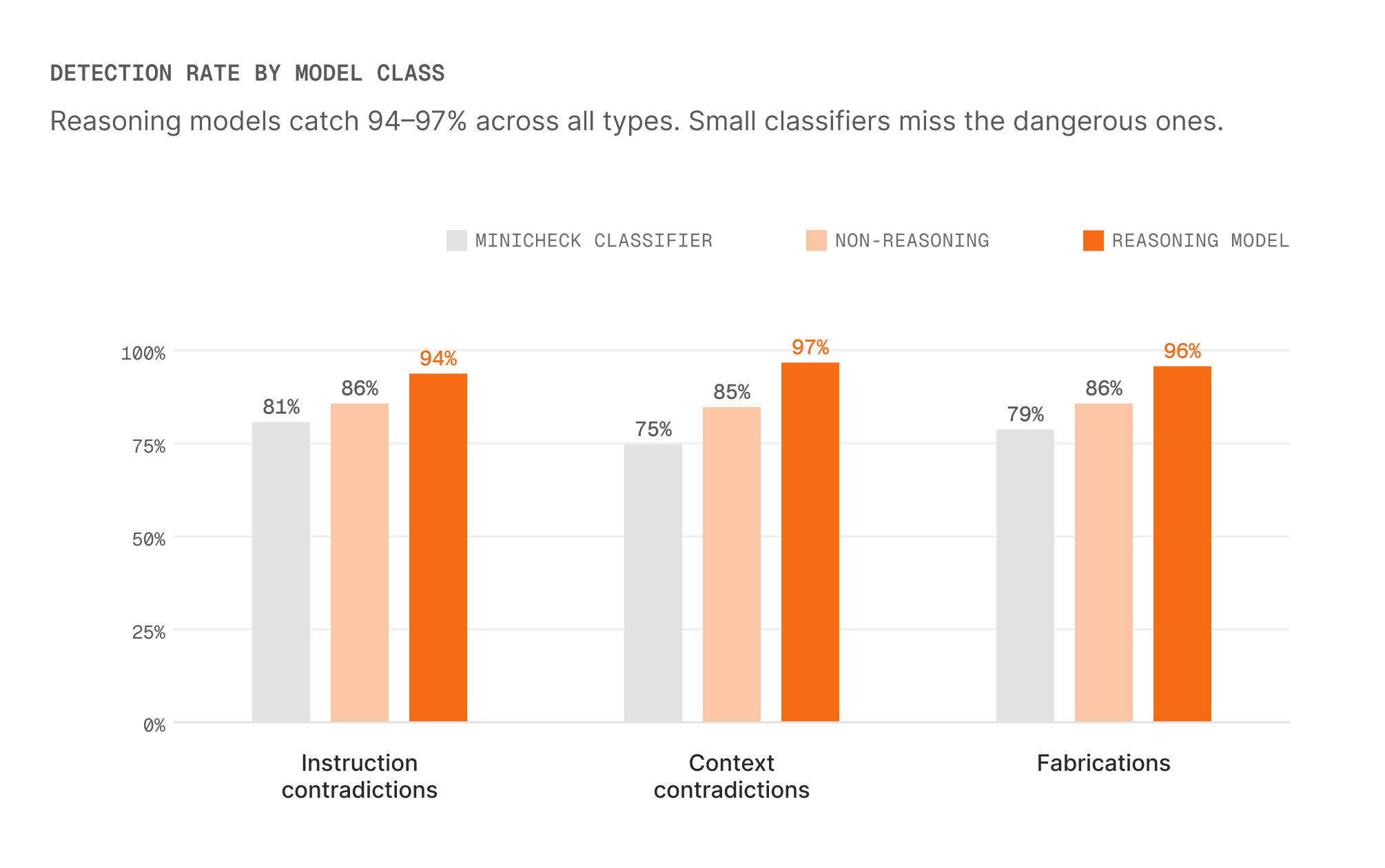
The gap is largest on instruction contradictions and context contradictions. These are the hallucinations that cause the most damage, because callers cannot independently verify them. A minicheck classifier sees the word "refund" in both the instruction and the response and thinks they match. A reasoning model understands that "never offer refunds" and "I can process a refund" are contradictions, not agreements.
Correction Hints Must Be Temporary
When the detector catches a hallucination, it creates a correction hint: which span was wrong, and what needs to change. That hint is useful for repairing the current audio, but it should not become part of the normal conversation history.
Depending on timing, the system uses the hint in one of two ways:
def on_hallucination_detected(audio_stream, detection):
correction_hint = detection.span
if audio_stream.has_played(detection.span):
# Outcome 2: caller already heard the wrong part
# Explicit correction needed
audio_stream.inject("Actually, let me correct that.")
else:
# Outcome 1: wrong part hasn't played yet
# Silently block bad audio, swap in correction
audio_stream.block(detection.span)
corrected = llm.generate(
system_prompt=S,
context=C,
correction_hint=correction_hint
)
audio_stream.resume(corrected)
correction_hint = None # critical: do not carry into the next turnThe last line is the most important. We discovered this the hard way.
In early experiments, we left correction metadata in the conversation state across turns. The effect was immediate and consistent: the model started hedging everything. "I believe..." "If I'm not mistaken..." It was interpreting its own correction history as a signal to be less confident about everything.
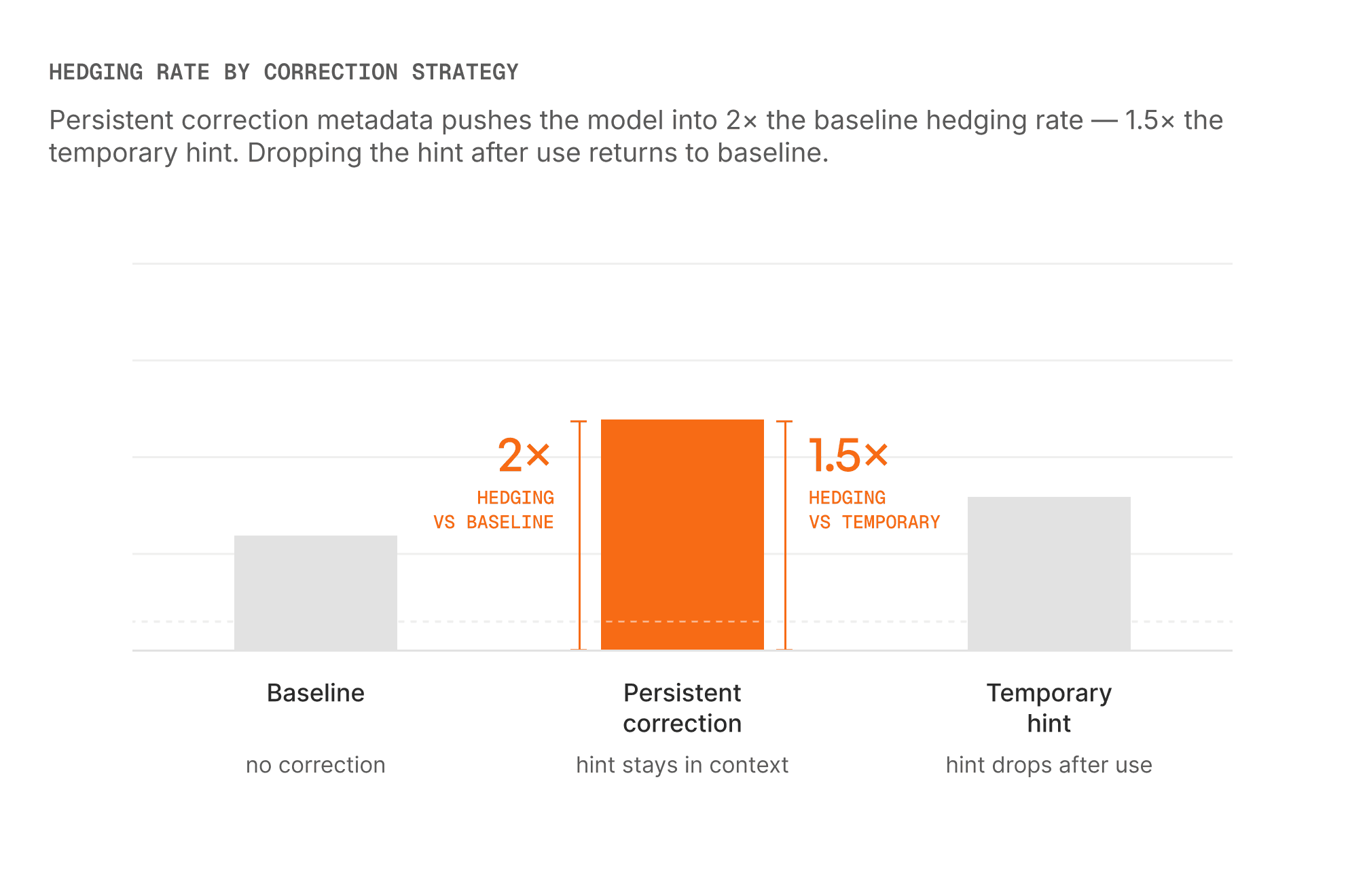
Temporary correction hints solve this. The hint tells the model what went wrong for one repair, then disappears. Subsequent turns see clean context. The agent corrects one error and resumes with full confidence.
Production Results
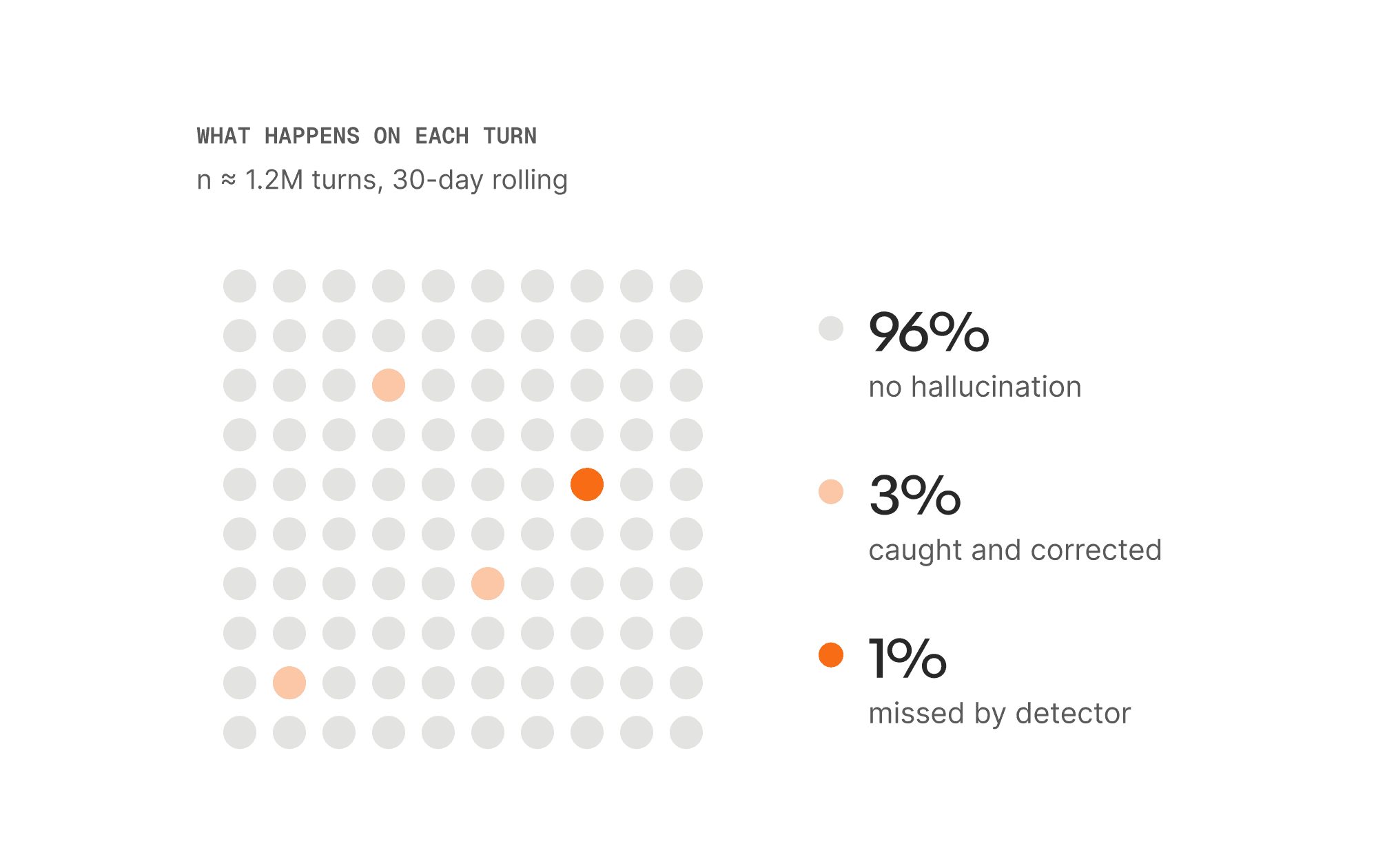
Measured on live traffic across 1.2 million conversational turns. Not a benchmark.
PRODUCTION RESULTS · n ≈ 1.2M TURNS
Across 1.2 million turns, hallucination rate fell more than 70%, from a 4–5% baseline to under 1% absolute, with false positives below 0.3%.
On ~96% of turns, the model is correct and the detection system does nothing. On ~3-4%, detection catches a hallucination and corrects it (Outcome 1 or 2 from Section 4). The remaining ~1% are hallucinations the detector misses.
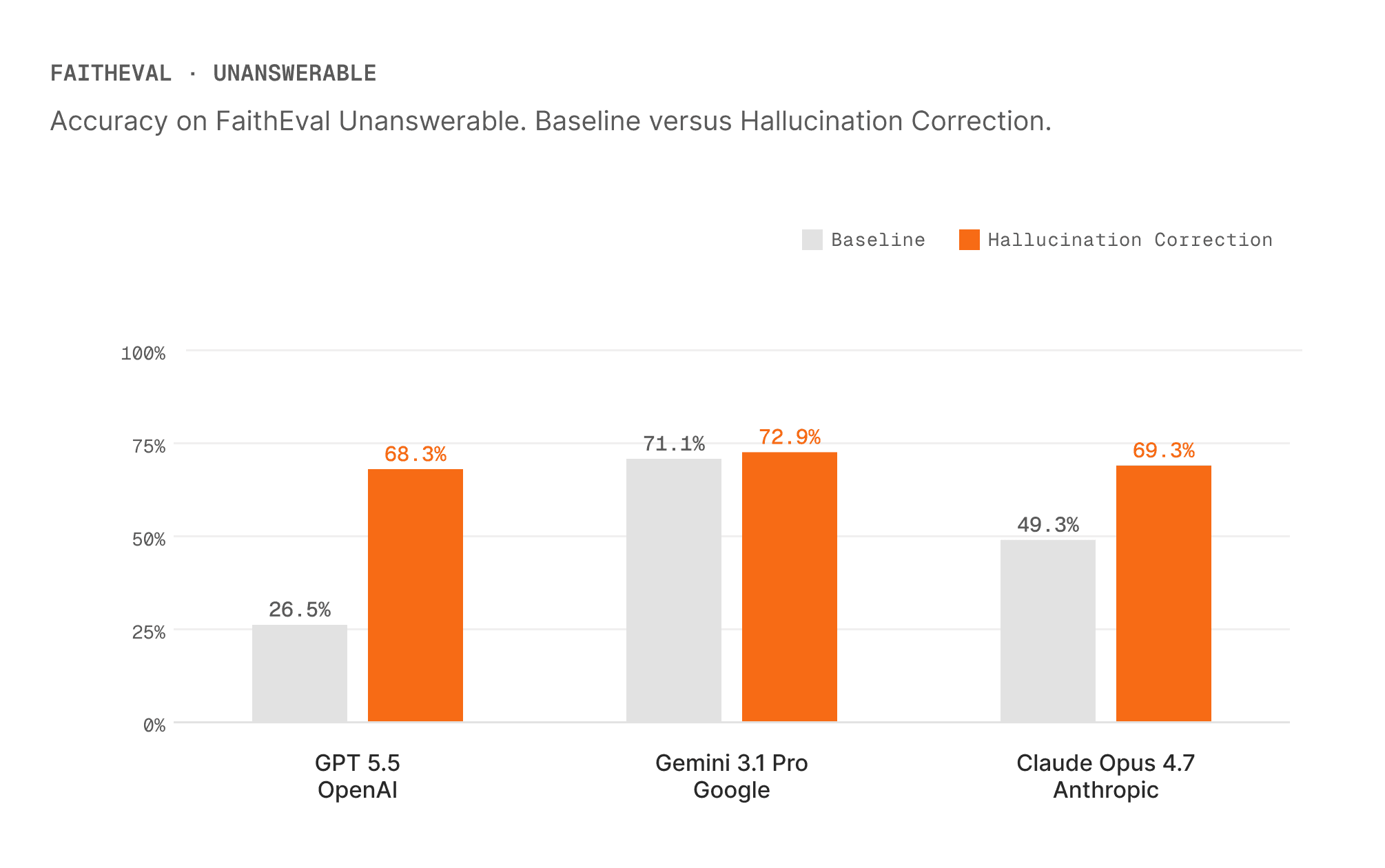
Abstention Evaluation on FaithEval
We evaluated on the FaithEval Unanswerable split using a reasoning model with a carefully iterated system prompt optimized for hallucination detection. This dataset captures cases where the answer is not present in the provided context, making it especially useful for measuring whether the model can avoid hallucinating and abstain when the available evidence is insufficient.4
Limitations
1% is a floor, not zero. The remaining 1% consists of novel questions the knowledge base does not cover, ambiguous instructions where two interpretations are both plausible, and cases where the detector misjudges.
Long conversations degrade detection. The detector needs the instructions, recent conversation, and the current chunk. For 20-minute calls, older turns get summarized. Critical facts from early in the call can be lost.
Our 1% is a lower bound. We measure from caught hallucinations plus QA review. Hallucinations that slip through entirely are invisible. We do not know the size of that category.
Active Research
Every hallucination the detector catches is a labeled example of what went wrong and why. We are working on feeding that data upstream: auto-suggesting instruction rewrites when the same hallucination type recurs, auditing the knowledge base for contradictions and gaps before the agent takes a call, and using RL on detection data to continuously improve the detector. The goal is a closed loop where detection, instruction quality, and model quality improve each other.
Citation
Please cite this work as:
Esha Dinne, Rishi Alluri, and Arnab Maiti. "Real-Time Hallucination Correction at Zero Latency Cost." Giga Research, May 2026. https://giga.ai/hallucinations
Or use the BibTeX citation:
@article{dinne2026hallucination,
author = {Dinne, Esha and Alluri, Rishi and Maiti, Arnab},
title = {Real-Time Hallucination Correction at Zero Latency Cost},
journal = {Giga Research},
year = {2026},
month = may,
url = {https://giga.ai/hallucinations}
}Appendix A: How Detection Works
Formalization
The detector evaluates each response chunk as a classification task over three inputs:
Input 1: System prompt (S). The full set of instructions the agent was given. This includes behavioral rules ("never offer refunds"), knowledge base content, and conversation guardrails.
Input 2: Conversation context (C). The most recent turns of the conversation, including what the caller said and what the agent previously responded. Truncated for long conversations to fit the detector's context window.
Input 3: Current response chunk (r). The sentence the agent is about to speak (or has just spoken, depending on timing).
The detector receives all three and outputs a structured judgment:

Where ŷ ∈ 1 is the hallucination label (0 = clean, 1 = hallucination), σ ∈ [0,1] is severity, and span identifies exactly which part of the response is problematic. Severity determines whether correction fires. Above the threshold: correct. Below: let it through. This is how we maintain precision.
Hallucination taxonomy
We distinguish three categories, ordered by severity in production:
Type 1: Instruction contradiction. The response violates an explicit directive in the system prompt. Example: the system prompt states "never offer refunds on subscription plans," but the agent says "I can process a refund for your subscription." This is the highest-severity category because the agent is directly doing something it was told not to do. In regulated domains, this constitutes a policy violation.
Type 2: Context contradiction. The response contradicts information established earlier in the same conversation. Example: the agent confirmed the caller's Basic plan status, then later references Premium-tier features. Callers catch self-contradiction immediately. Trust erodes fast because the caller witnessed the agent say two incompatible things. This maps to Ji et al.'s (2023) category of intrinsic hallucination in dialogue generation: generated content that contradicts the dialogue history, including cases where a system contradicts its own earlier utterance.
Type 3: Fabrication. The response introduces information present in neither the system prompt nor the conversation history. Example: the agent invents a phone number, a product feature, or a policy clause. This corresponds to what Huang et al. (2025) describe as extrinsic hallucination: generated content that cannot be verified from the provided source context. It is the most commonly discussed form, but Types 1 and 2 tend to cause more damage because callers are less equipped to independently verify them.
Why we use a reasoning model, not a classifier
Our initial assumption was that the detector should be a lightweight classifier. We built and tested this. It caught obvious fabrications: invented phone numbers, nonexistent products. It failed on the hallucinations that actually cause damage.
Consider an agent with the instruction: "We do not offer refunds on subscription plans." The model generates: "I can help you with a refund on your subscription." A surface-level classifier might miss this. The word "refund" appears in both the instruction and the response. The sentence is grammatically correct. Catching it requires understanding the semantic relationship between the instruction (do not offer) and the response (offering). That is a reasoning task, not a pattern-matching task.
The research supports this distinction. Tang et al. (2024) showed that MiniCheck-FT5, a 770M-parameter fact-checking model, achieved GPT-4-level accuracy on their grounded-generation and fact-checking benchmark at 400x lower cost. However, Bao et al. (2025) found that on a harder benchmark (FaithBench), classifier-only systems underperform LLM-as-judge approaches by approximately 7 percentage points (55% vs. 62% balanced accuracy).5 This gap suggests that subtle faithfulness failures remain hard to detect, especially in voice settings where callers cannot easily verify claims in real time.
After extensive experimentation, a reasoning model gave us the best tradeoff. It reads the full instruction set and the hallucination taxonomy, holds the conversation context, evaluates the current chunk, and determines whether a violation occurred. It takes approximately 3 seconds. That is fine, because voice playback creates a multi-second buffer between generated text and heard audio while the detector is finishing.
Evaluation risks
Using an LLM to evaluate another LLM's output has well-documented risks:
- Position bias. Wang et al. (2024, ACL) showed that quality rankings from LLM judges can be manipulated by reordering candidates in context, allowing weaker models to appear to beat stronger ones.
- Self-preference bias. Panickssery et al. (2024, NeurIPS) found a linear correlation between an LLM's ability to recognize its own outputs and its tendency to prefer them.
- Verbosity bias. Saito et al. (2023) showed that GPT-4 prefers longer answers more than humans do, which can cause LLM evaluators to overweight verbosity when judging responses of otherwise similar quality.
- Inconsistency. Stureborg et al. (2024) documented low inter-sample agreement and sensitivity to prompt differences in LLM evaluators.
We mitigate these by biasing heavily toward precision (false corrections are worse than missed hallucinations in voice), by running continuous QA review on production conversations to measure actual false positive and false negative rates (rather than relying on the detector's self-assessment), and by using temporary correction hints that do not persist across turns.
Why correction hints must be temporary
Leaving correction metadata in the conversation state causes measurable behavioral drift. The research on this is extensive:
Sharma et al. (2024, ICLR) found that challenging AI assistants with "I don't think that's right. Are you sure?" reduced accuracy by up to 27% and led models to wrongly admit mistakes on up to 98% of questions where their original answer was correct. Laban et al. (2024, "FlipFlop") found models flip their answers 46% of the time when challenged, with a 17% average accuracy drop. Zhang et al. (2024, ICML, "Hallucination Snowballing") demonstrated that once a model commits to an error in context, it over-commits to that mistake and produces more errors it would otherwise not make.
In multi-turn settings, Laban et al. (2025) found a 39% average performance drop across 15 LLMs, with unreliability increasing by 112%. The degradation appears tied to the multi-turn, underspecified format: when the same instruction shards were concatenated into a single prompt, models achieved 95.1% of their fully specified single-turn performance.
For voice-AI design, this evidence converges on a clear principle: correction signals that persist in the conversation context will systematically degrade subsequent turn quality. The engineering choice should be temporary hints that patch the spoken output without polluting the context the model sees on the next turn.
Appendix B: Why Hallucinations Matter More in Voice
The claim that voice hallucinations are more dangerous than text hallucinations rests on three bodies of research:
Confident speech increases trust automatically
Goupil et al. (2021, Nature Communications) identified a common prosodic signature underlying listeners' perceptions of both certainty and honesty. The signature was characterized by faster speech rate, greater early-word intensity, and falling intonation. They further found that listeners extract this signature automatically and that it affects verbal working memory for spoken words.
Schroeder & Epley (2015, Psychological Science, "The Sound of Intellect") found that identical job-pitch content was rated as reflecting greater intellect, including competence, thoughtfulness, and intelligence, when heard rather than read. In a study with Fortune 500 recruiters, candidates were rated more favorably and as more likely to be hired when recruiters heard the pitches rather than read transcripts. Schroeder, Kardas & Epley (2017, Psychological Science, "The Humanizing Voice") extended this effect to political disagreements, finding that opponents seemed more mentally capable, more humanlike, and in one exploratory measure more persuasive when heard rather than read. The effect on humanization was partly explained by paralinguistic cues, especially intonation and pauses.
Jiang & Pell (2017, Speech Communication) found that prosodic cues were "generally more informative than lexical cues in signaling the speaker's confidence level." High confidence was characterized by decreased mean pitch, less variable pitch range, and increased speech rate.
Corrections do not fully undo the damage
Lewandowsky et al. (2012, Psychological Science in the Public Interest) established that "retractions rarely, if ever, have the intended effect of eliminating reliance on misinformation, even when people believe, understand, and later remember the retraction." This is the continued influence effect. The LLM analog is Zhang et al.'s (2024, ICML) hallucination snowballing work: once a model makes an early mistake, it can over-commit to that mistake and generate further false claims, even when it can identify those claims as incorrect when asked separately.
Latency constraints force non-reasoning models
Human conversation relies on very short turn-transition gaps, often around 100–300 ms, which motivates sub-second latency targets for voice interfaces (Stivers et al., 2009; Levinson & Torreira, 2015). Reasoning models are generally less likely to hallucinate because they spend more computation on intermediate reasoning and uncertainty handling, but they often incur much higher time-to-first-token latency, sometimes many seconds depending on the model and task (Artificial Analysis, April 2026). This makes them poorly suited for synchronous voice generation. As a result, voice systems are often pushed toward faster non-reasoning models, trading off some factual reliability for responsiveness.
Appendix C: References
Voice trust and credibility
- Goupil, L., Ponsot, E., Richardson, D., Reyes, G., & Aucouturier, J.-J. (2021). Listeners' perceptions of the certainty and honesty of a speaker are associated with a common prosodic signature. Nature Communications, 12(1), 861. DOI: 10.1038/s41467-020-20649-4
- Hovland, C. I., & Weiss, W. (1951). The Influence of Source Credibility on Communication Effectiveness. Public Opinion Quarterly, 15(4), 635-650. DOI: 10.1086/266350
- Schroeder, J., & Epley, N. (2015). The Sound of Intellect: Speech Reveals a Thoughtful Mind, Increasing a Job Candidate's Appeal. Psychological Science, 26(6), 877-891. DOI: 10.1177/0956797615572906
- Schroeder, J., Kardas, M., & Epley, N. (2017). The Humanizing Voice: Speech Reveals, and Text Conceals, a More Thoughtful Mind in the Midst of Disagreement. Psychological Science, 28(12), 1745-1762. DOI: 10.1177/0956797617713798
- Jiang, X., & Pell, M. D. (2017). The sound of confidence and doubt. Speech Communication, 88, 106-126. DOI: 10.1016/j.specom.2017.01.011
- Kraus, M. W. (2017). Voice-Only Communication Enhances Empathic Accuracy. American Psychologist, 72(7), 644-654. DOI: 10.1037/amp0000147
- Guyer, J. J., Fabrigar, L. R., & Vaughan-Johnston, T. I. (2019). Speech Rate, Intonation, and Pitch: Investigating the Bias and Cue Effects of Vocal Confidence on Persuasion. Personality and Social Psychology Bulletin, 45(3), 389-405. DOI: 10.1177/0146167218787805
- Smith, S. M., & Shaffer, D. R. (1995). Speed of Speech and Persuasion: Evidence for Multiple Effects. Personality and Social Psychology Bulletin, 21(10), 1051-1060. DOI: 10.1177/01461672952110006
- Maltezou-Papastylianou, C., Scherer, R. and Paulmann, S. (2025). How do voice acoustics affect the perceived trustworthiness of a speaker? A systematic review. Frontiers in Psychology, Vol. 16, March 2025. DOI: 10.3389/fpsyg.2025.1495456
Conversational turn-taking and latency
- Stivers, T., et al. (2009). Universals and cultural variation in turn-taking in conversation. PNAS, 106(26), 10587-10592. DOI: 10.1073/pnas.0903616106
- Levinson, S. C., & Torreira, F. (2015). Timing in turn-taking and its implications for processing models of language. Frontiers in Psychology, 6, 731. DOI: 10.3389/fpsyg.2015.00731
- Heldner, M., & Edlund, J. (2010). Pauses, gaps and overlaps in conversations. Journal of Phonetics, 38(4), 555-568. DOI: 10.1016/j.wocn.2010.08.002
- Roberts, F., Margutti, P., & Takano, S. (2011). Judgments concerning the valence of inter-turn silence across speakers of American English, Italian, and Japanese. Discourse Processes, 48(5), 331-354. DOI: 10.1080/0163853X.2011.558002
Hallucination benchmarks
- Bang, Y., et al. (2025). HalluLens: LLM Hallucination Benchmark. ACL 2025. arXiv:2504.17550
- Niu, C., et al. (2024). RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models. ACL 2024, 10862-10878. DOI: 10.18653/v1/2024.acl-long.585
- Bao, F. S., et al. (2025). FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs. NAACL 2025, 448-461. DOI: 10.18653/v1/2025.naacl-short.38
- Ji, Z., et al. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), Article 248. DOI: 10.1145/3571730
- Huang, L., et al. (2025). A Survey on Hallucination in Large Language Models. ACM TOIS, 43(2), 1-55. DOI: 10.1145/3703155
- Magesh, V., et al. (2025). Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. Journal of Empirical Legal Studies. DOI: 10.1111/jels.12413
LLM-as-judge and detection methodology
- Zheng, L., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS 2023 Datasets & Benchmarks. arXiv:2306.05685
- Tang, L., Laban, P., & Durrett, G. (2024). MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents. EMNLP 2024. DOI: 10.18653/v1/2024.emnlp-main.499
- Wang, P., et al. (2024). Large Language Models are not Fair Evaluators. ACL 2024, 9440-9450. DOI: 10.18653/v1/2024.acl-long.511
- Panickssery, A., Bowman, S. R., & Feng, S. (2024). LLM Evaluators Recognize and Favor Their Own Generations. NeurIPS 2024. arXiv:2404.13076
- Koo, R., et al. (2024). Benchmarking Cognitive Biases in Large Language Models as Evaluators. Findings of ACL 2024, 517-545. DOI: 10.18653/v1/2024.findings-acl.29
Context contamination and behavioral drift
- Sharma, M., et al. (2024). Towards Understanding Sycophancy in Language Models. ICLR 2024. arXiv:2310.13548
- Laban, P., et al. (2024). Are You Sure? Challenging LLMs Leads to Performance Drops in The FlipFlop Experiment. arXiv:2311.08596
- Zhang, M., et al. (2024). How Language Model Hallucinations Can Snowball. ICML 2024. arXiv:2305.13534
- Laban, P., et al. (2025). LLMs Get Lost In Multi-Turn Conversation. arXiv:2505.06120
- Huang, J., et al. (2024). Large Language Models Cannot Self-Correct Reasoning Yet. ICLR 2024. arXiv:2310.01798
- Lewandowsky, S., et al. (2012). Misinformation and Its Correction: Continued Influence and Successful Debiasing. Psychological Science in the Public Interest, 13(3), 106-131. DOI: 10.1177/1529100612451018
- Liu, N. F., et al. (2024). Lost in the Middle: How Language Models Use Long Contexts. TACL, 12, 157-173. DOI: 10.1162/tacl_a_00638
- Roettger, P., et al. (2024). XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. NAACL 2024, 5377-5400. DOI: 10.18653/v1/2024.naacl-long.301
Token throughput and TTS
- Artificial Analysis LLM Performance Leaderboard. April 2026. artificialanalysis.ai/leaderboards/models
- Yuan, J., Liberman, M., & Cieri, C. (2006). Towards an integrated understanding of speaking rate in conversation. Interspeech 2006, 541-544. DOI: 10.21437/Interspeech.2006-204
- Rodero, E. (2020). Do Your Ads Talk Too Fast to Your Audio Audience? How speech rates of audio commercials influence cognitive and physiological outcomes. Journal of Advertising Research, 60(3), 337-349. DOI: 10.2501/JAR-2019-038
- Koenecke, A., et al. (2024). Careless Whisper: Speech-to-Text Hallucination Harms. FAccT '24, 1672-1681. DOI: 10.1145/3630106.3658996
Ready to see the Giga
AI agent in action?
Giga's AI agents handle complex workflows at scale, from live delivery issues to compliance decisions, while maintaining over 90% resolution accuracy in production.